

Rawnak Tanzim
Military Institute of Science & Technology (MIST)
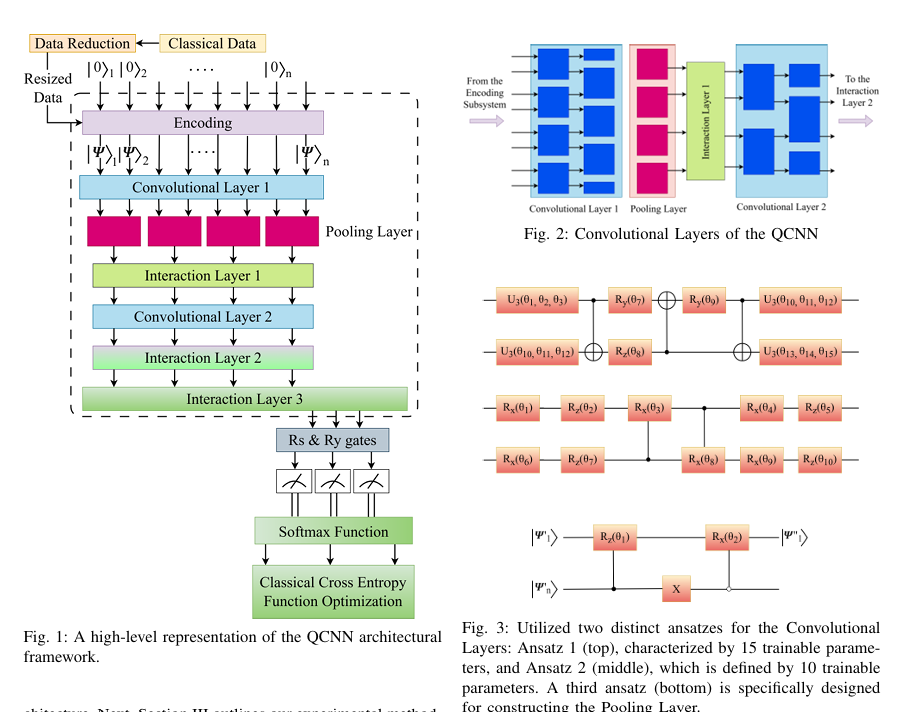
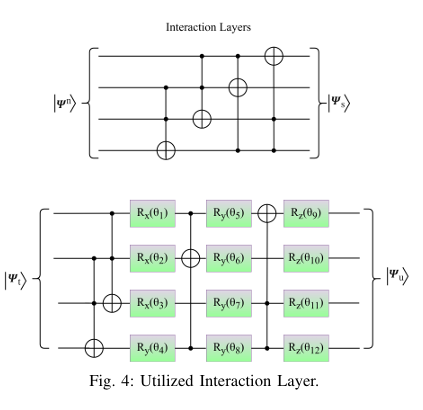
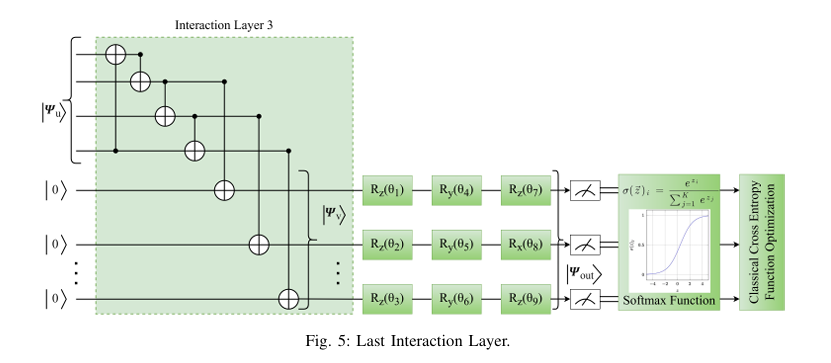
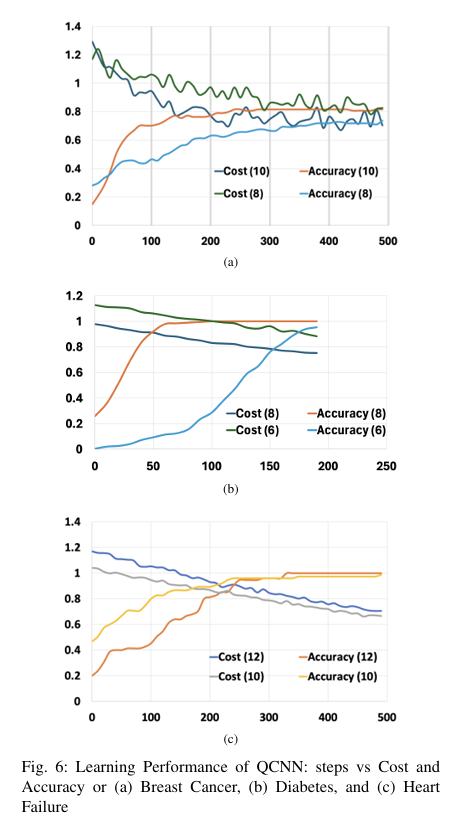
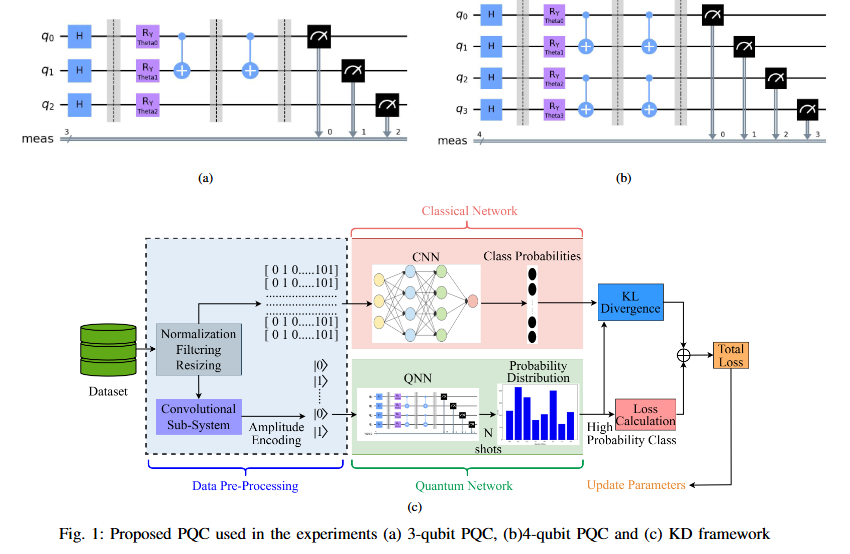
Quantum computing holds considerable promise for artificial intelligence (AI) in clinical decision support systems (CDSS), particularly in resource-constrained environments. This paper investigates a multiqubit quantum convolutional neural network (MQ-CNN) for medical diagnostics, leveraging param eterized quantum circuits to process low-resource healthcare datasets. We evaluate the framework on three binary classifica tion tasks: breast cancer (Wisconsin dataset), diabetes (Pima In dians), and heart failure prediction, using angle-encoded clinical features. The MQ-CNN achieves test accuracies of 82.4%, 98.7%, and 97.3% respectively, matching classical CNNs while reducing trainable parameters significantly. Comparative analysis shows the quantum model converges 22% faster than hybrid quantum classical counterparts under identical training conditions. Ro bustness evaluations confirm ≤3% accuracy degradation when subjected to 15% synthetic label noise. These results highlight the architecture’s suitability for resource-constrained environ ments, demonstrating that quantum-enhanced feature extraction can maintain diagnostic accuracy while significantly reducing computational overhead. This work provides empirical evidence for near-term quantum machine learning in practical healthcare applications.
@INPROCEEDINGS{11172247,
author={Ovi, Tareque Bashar and Bashree, Nomaiya and Alam, Ayat Subah and Tanzim, Rawnak and Wahed, Md Abdul and Nyeem, Hussain},
booktitle={2025 International Conference on Quantum Photonics, Artificial Intelligence, and Networking (QPAIN)},
title={Multiqubit Quantum Convolutional Neural Networks for Efficient AI-Driven Healthcare Analytics},
year={2025},
volume={},
number={},
pages={1-6},
keywords={Degradation;Decision support systems;Accuracy;Computational modeling;Qubit;Noise;Neural networks;Computer architecture;Feature extraction;Convolutional neural networks;Deep learning;QML;QCNN;feature interaction;qubit;health AI},
doi={10.1109/QPAIN66474.2025.11172247}}
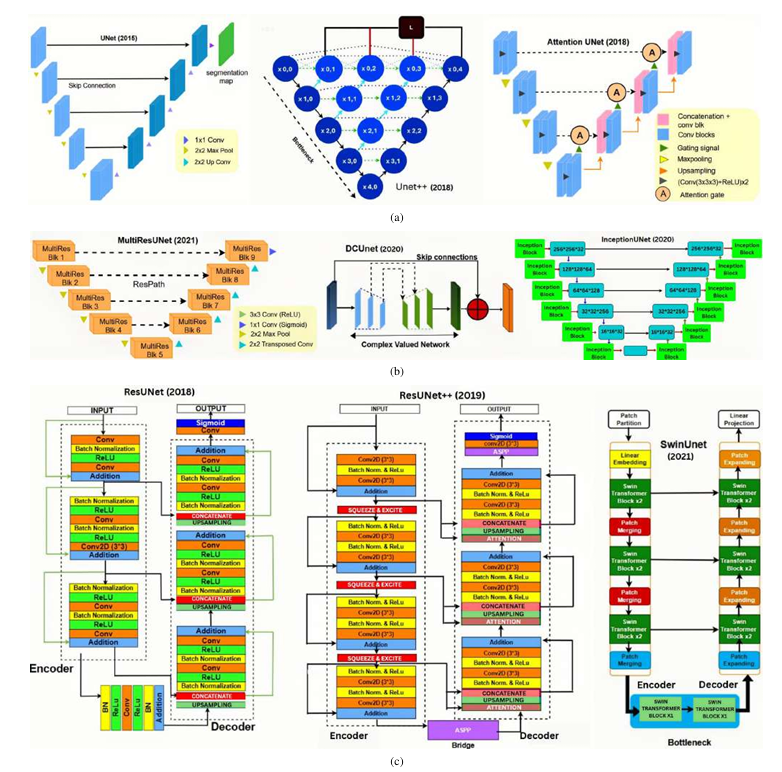
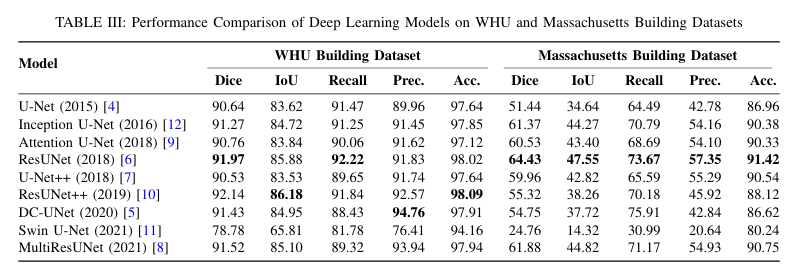
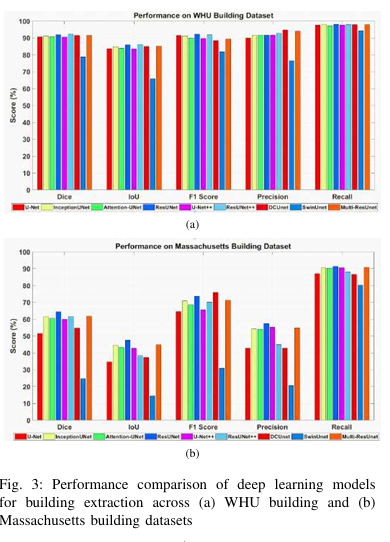
Cross-domain variations in satellite imagery-ranging from sensor characteristics to urban morphology-undermine the reliability of deep segmentation models. We isolate the architectural factor of residual connections by comparing nine encoder-decoder designs, trained from scratch on the large-scale WHU and the compact Massachusetts building datasets without pretrained backbones or patch augmentation. Residual architectures (ResUNet, ResUNet++) consistently lead by margin: up to 1.6 % higher Dice and 2.5% higher IoU on WHU dataset, and a 5% Dice gain on Massachusetts dataset. Error-mode analysis shows that skip-augmented identity mappings preserve feature gradients across depth, reducing false negatives by as much as 12 % versus vanilla U-Net under data scarcity. These results demonstrate that residual links are a simple yet powerful strategy to fortify building segmentation against domain shifts in real-world satellite imagery.
S. B. Zahid, R. Tanzim, T. B. Ovi, N. Bashree, H. Nyeem and M. A. Wahed, "Impact of Residual Connections on Cross-Domain Generalization for Building Segmentation," 2025 International Conference on Quantum Photonics, Artificial Intelligence, and Networking (QPAIN), Rangpur, Bangladesh, 2025, pp. 1-6, doi: 10.1109/QPAIN66474.2025.11172159. keywords: {Training;Attention mechanisms;Architecture;Semantic segmentation;Buildings;Transfer learning;Transformers;Feature extraction;Satellite images;Remote sensing;building extraction;remote sensing;semantic segmentation;aerial imagery;attention mechanism;transformer;transfer learning},
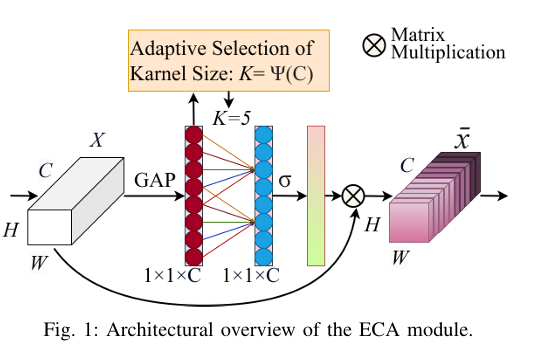
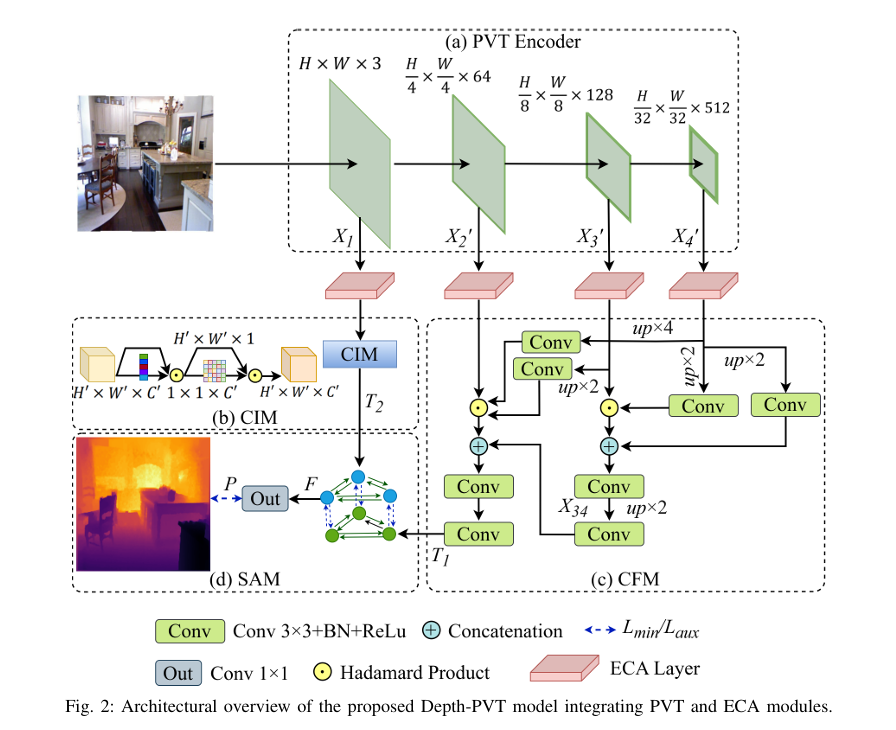
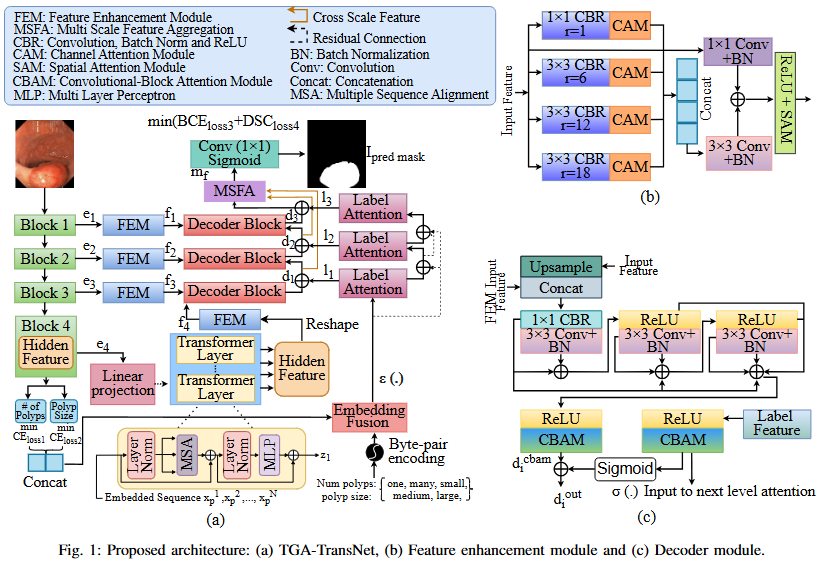
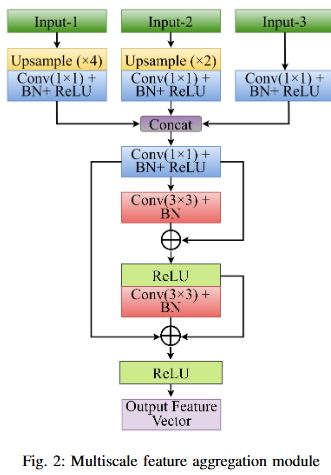
One of the most important machine vision tasks is monocular depth prediction, essential for applications such as autonomous navigation and augmented reality. While CNN-based architectures are widely used, they are limited by restricted receptive fields, which hinder effective multi-scale feature extraction. In order to overcome these issues, we develop Depth-PVT, an innovative architecture that integrates Efficient Channel Attention (ECA) with the Pyramid Vision Transformer (PVT). This integration enhances feature representation by emphasizing salient channel-wise features and suppressing irrelevant ones with minimal computational overhead. Depth-PVT incorporates three key modules within the PVT framework: the cascaded fusion module (CFM) for aggregating semantic and spatial information of high level features, the camouflage identification module (CIM) for capturing complex depth cues and low level features, and the similarity aggregation module (SAM) for fusing cross-scale features, thereby enriching depth d
@inproceedings{ovi2025depth,
title={Depth-PVT: Pyramid Vision Transformer with Channel Attention for Depth Estimation},
author={Ovi, Tareque Bashar and Bashree, Nomaiya and Tanzim, Rawnak and Tirtha, Anindya Chanda and Nyeem, Hussain and Wahed, Md Abdul},
booktitle={2025 International Conference on Electrical, Computer and Communication Engineering (ECCE)},
pages={1--6},
year={2025},
organization={IEEE}
}
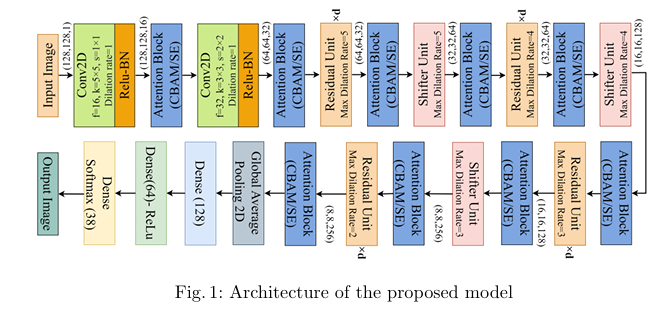
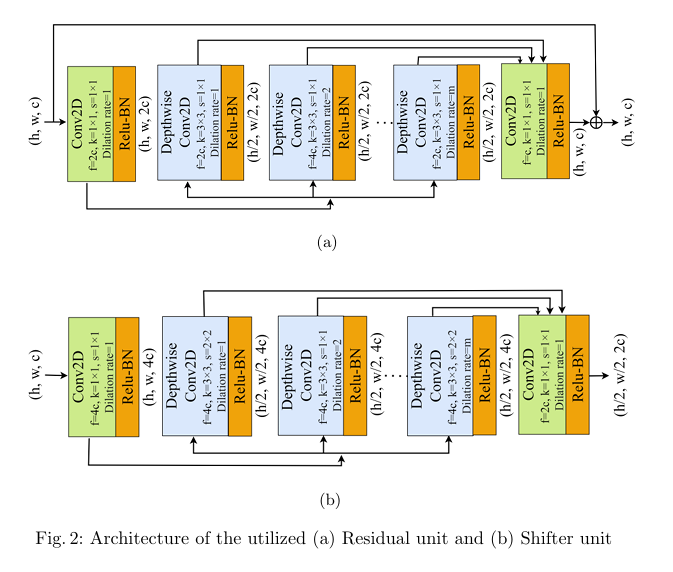
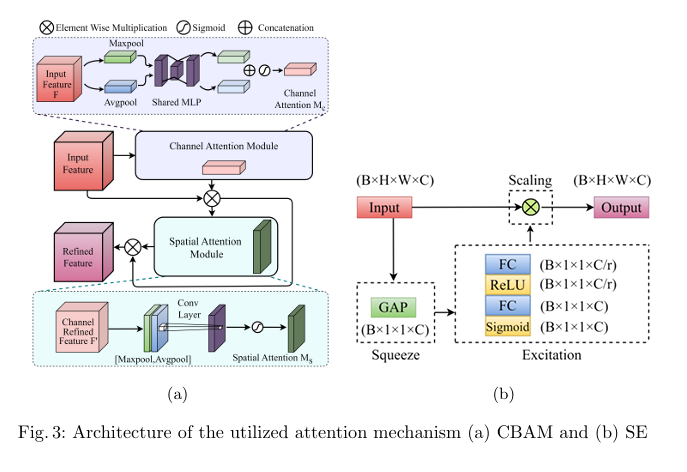
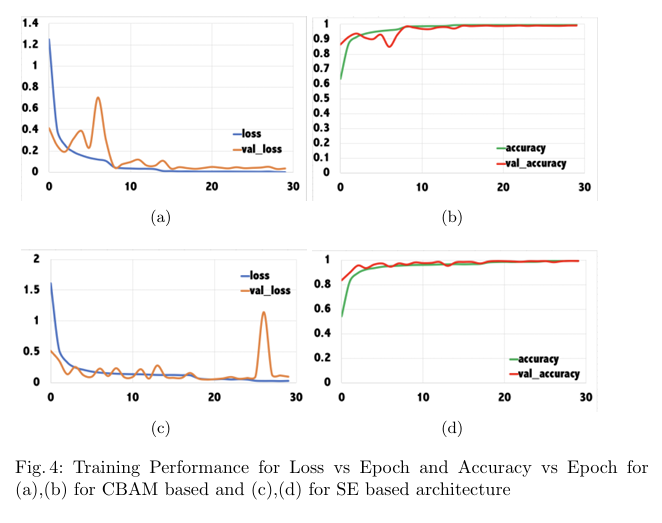
Plant diseases pose a significant threat to global food secu rity, demanding faster and more accessible methods for identification. While deep learning has shown promise in automating plant disease diagnosis from digital images, large model sizes remain a hurdle. This paper proposes a novel lightweight deep learning framework based on CovXNet, a convolutional neural network architecture utilizing efficient depthwise convolutions, combined with Squeeze-and-Excitation (SE) and Convolutional Block Attention Module (CBAM) attention mechanisms for enhanced performance. Our proposed models have been evaluated on the publicly available Plant Village dataset, achieving state-of-the art performance with 99.37% test accuracy using CovXNet with SE and 99.30% using CovXNet with CBAM across 38 classes. These re sults demonstrate the effectiveness of our approach in facilitating accu rate and efficient plant disease diagnosis, particularly for deployment on resource-constrained devices.
@inproceedings{chowdhury2024attention,
title={Attention-Enhanced Multi-dilation CNN for Plant Disease Classification},
author={Chowdhury, Disha and Bashree, Nomaiya and Ovi, Tareque Bashar and Nyeem, Hussain and Wahed, Md Abdul and Tanzim, Rawnak},
booktitle={International Conference on Human-Centric Smart Computing},
pages={111--121},
year={2024},
organization={Springer}
}
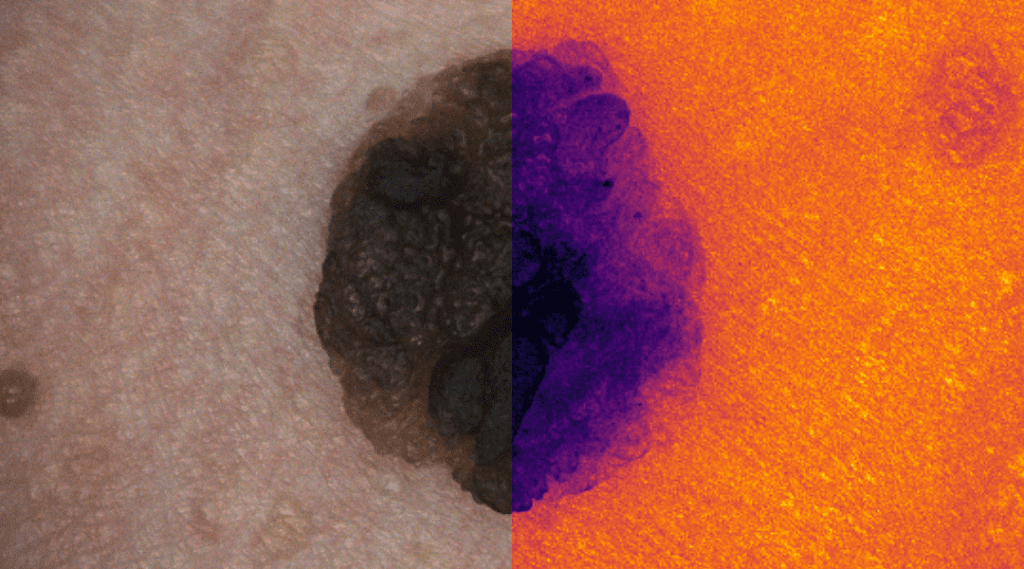
Deep learning for skin cancer relies on segmentation and classification.
This research area focuses on developing advanced deep learning frameworks for the automated detection, segmentation, and classification of skin lesions from dermoscopic and clinical images. By leveraging convolutional neural networks (CNNs) and transformer-based architectures, the goal is to differentiate malignant melanomas from benign skin conditions with high diagnostic accuracy. The research integrates explainable AI techniques to enhance clinical trust and decision support, ultimately contributing to early detection and improved patient outcomes in dermatological diagnostics.
No objective provided.
No findings listed yet.
No photos added.
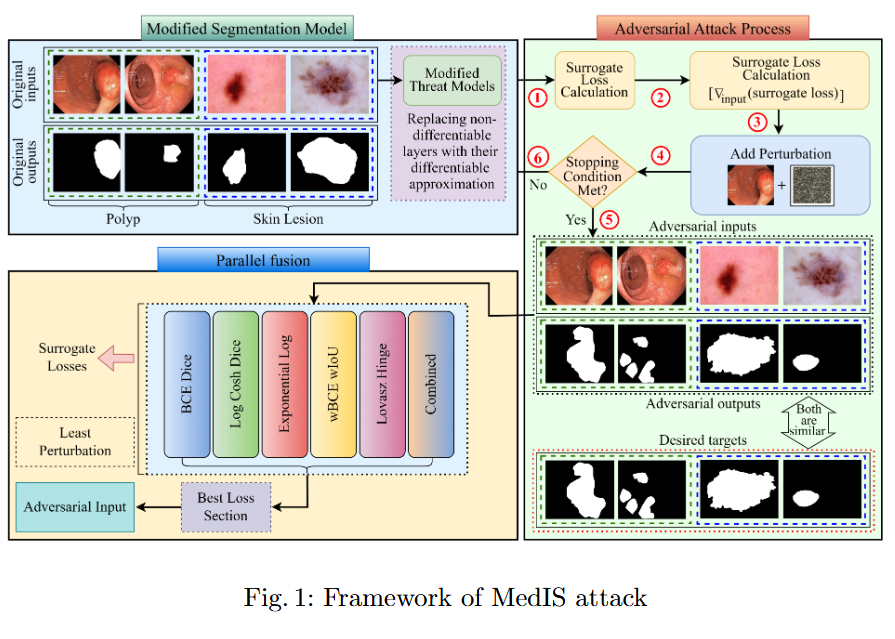
This study evaluates the robustness of leading segmentation models against advanced adversarial attacks in the context of polyp and skin lesion identification.
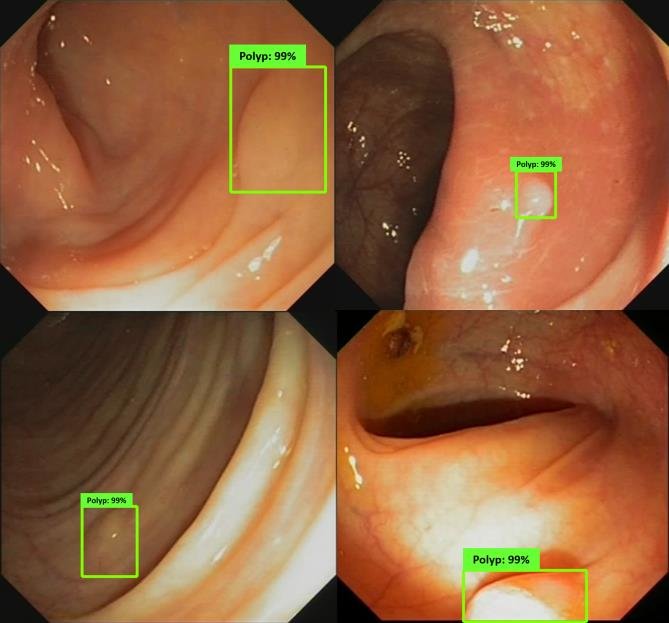
An AI "second eye" for real-time polyp detection during colonoscopy.
Research in colonoscopic polyp detection aims to design real-time AI-assisted systems for the early identification of colorectal polyps during colonoscopy. Using deep convolutional and attention-based segmentation models, the objective is to improve the sensitivity and precision of polyp localization under varying illumination, motion, and texture conditions. The developed models function as a “second observer” for endoscopists, assisting in diagnostic decisions and reducing the rate of missed polyps, thereby enhancing colorectal cancer prevention.
No selected projects in this area.
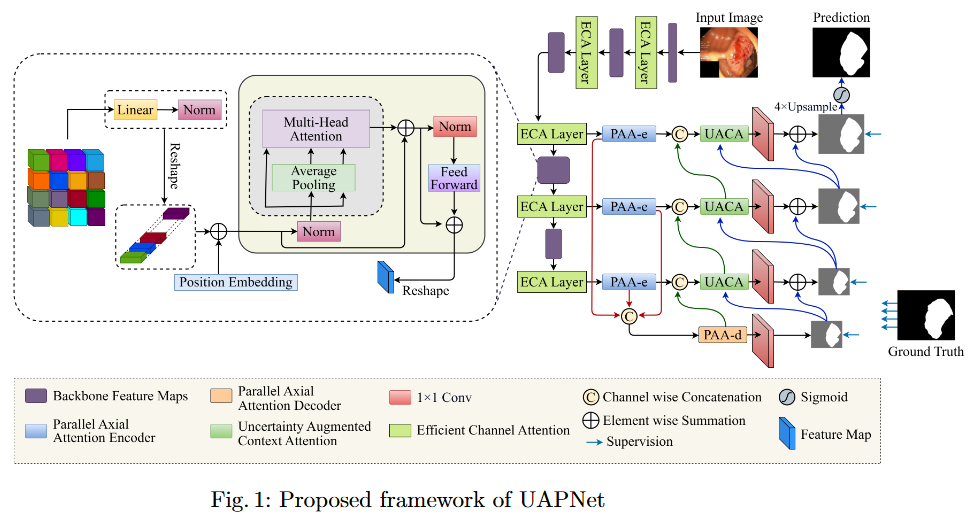
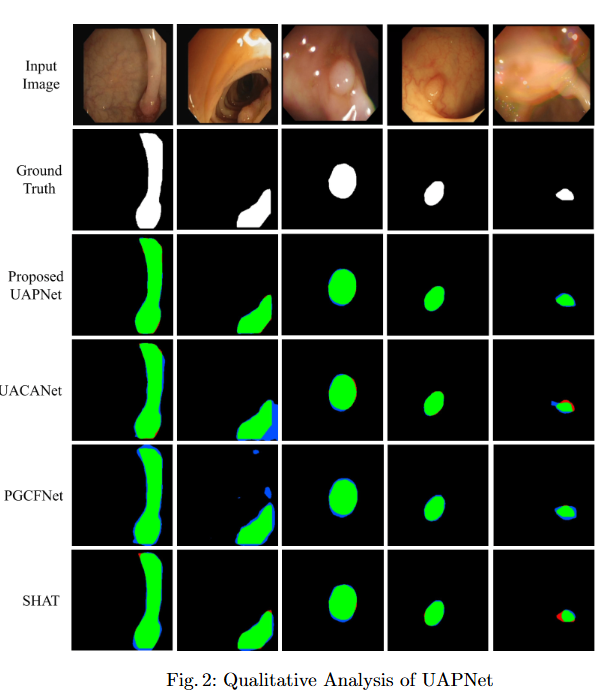
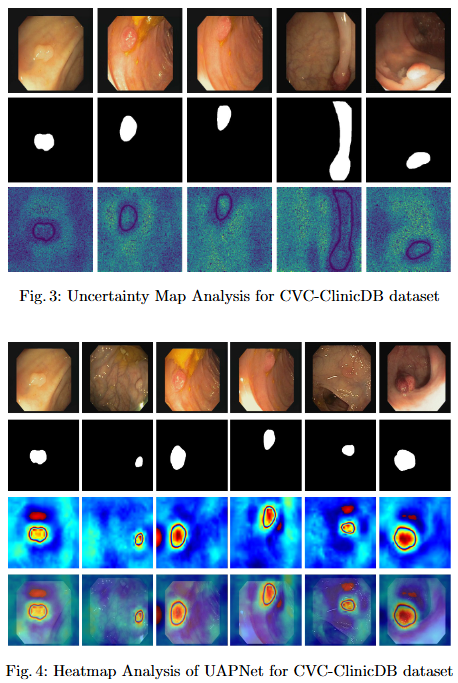
To mitigate feature redundancy in deep networks, we integrate the Efficient Channel Attention (ECA) module with the PVT encoder and augment it with an Uncertainty Augmented Context Attention (UACA) mechanism.
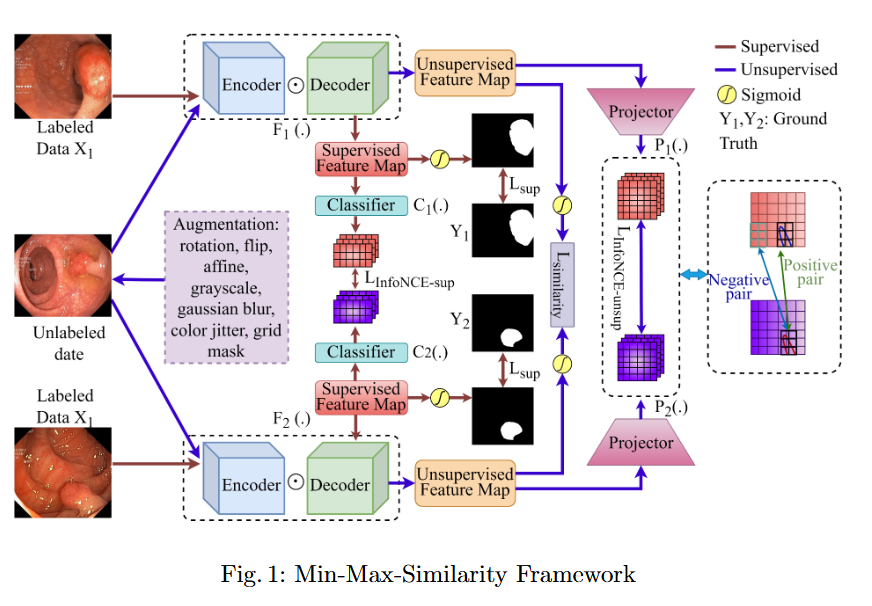
In this study, we systematically investigate how established supervised segmentation models perform within three representative semi-supervised frameworks: Min-Max Similarity, Duo-SegNet, and Deep Co-Training.
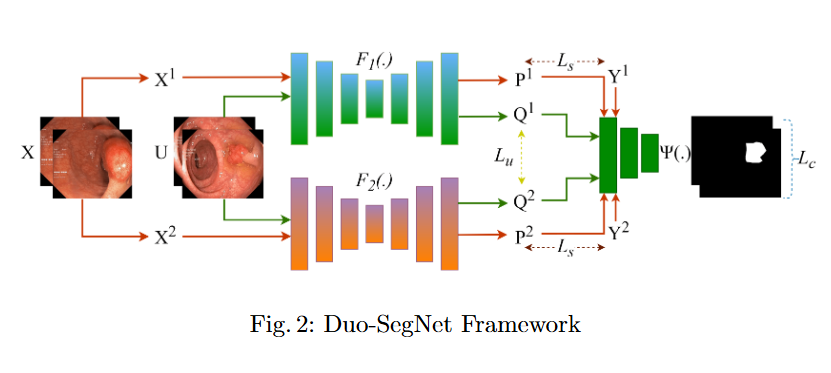
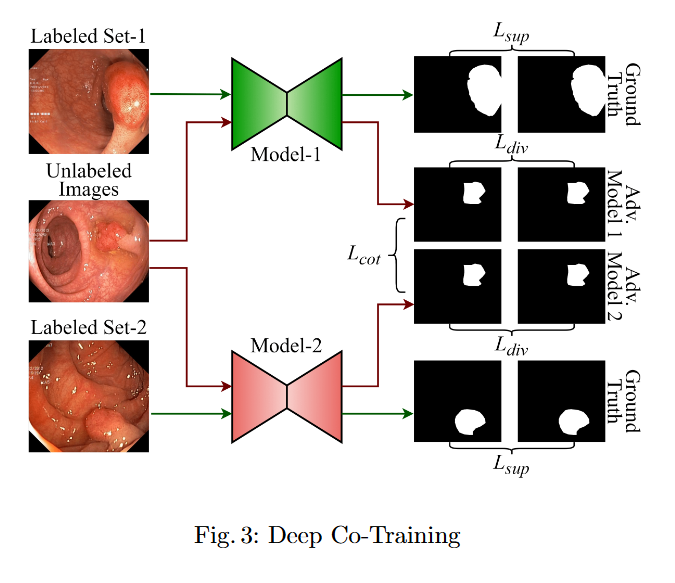
This study evaluates the robustness of leading segmentation models against advanced adversarial attacks in the context of polyp and skin lesion identification.
Imaging, segmentation, and diagnostics for medical data.
This area encompasses a broad spectrum of imaging modalities—MRI, CT, X-ray, and endoscopic imaging—to develop computational tools for segmentation, registration, and diagnostic interpretation. Research focuses on integrating multimodal image features with deep learning to improve disease localization and treatment planning. The emphasis is on constructing efficient, explainable, and data-driven models that support clinical workflows, thereby bridging the gap between medical imaging research and practical healthcare applications.
No objective provided.
No findings listed yet.
No objective provided.
No findings listed yet.
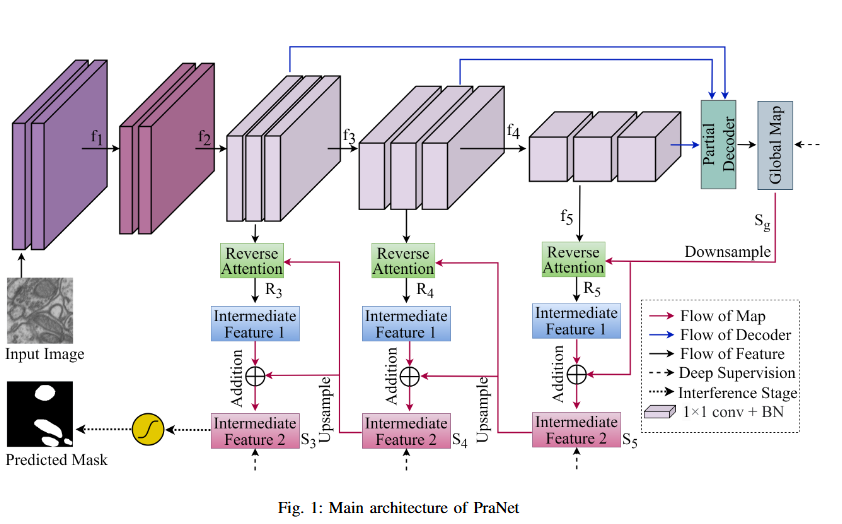
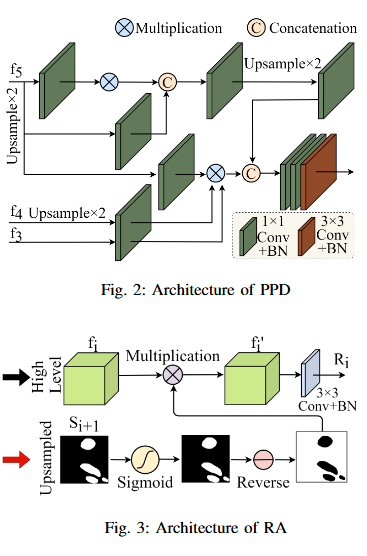
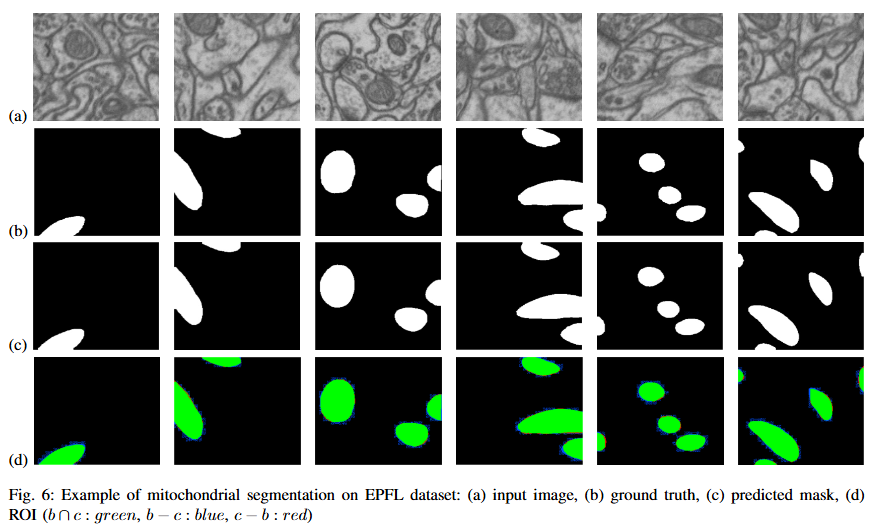
No objective provided.
No findings listed yet.
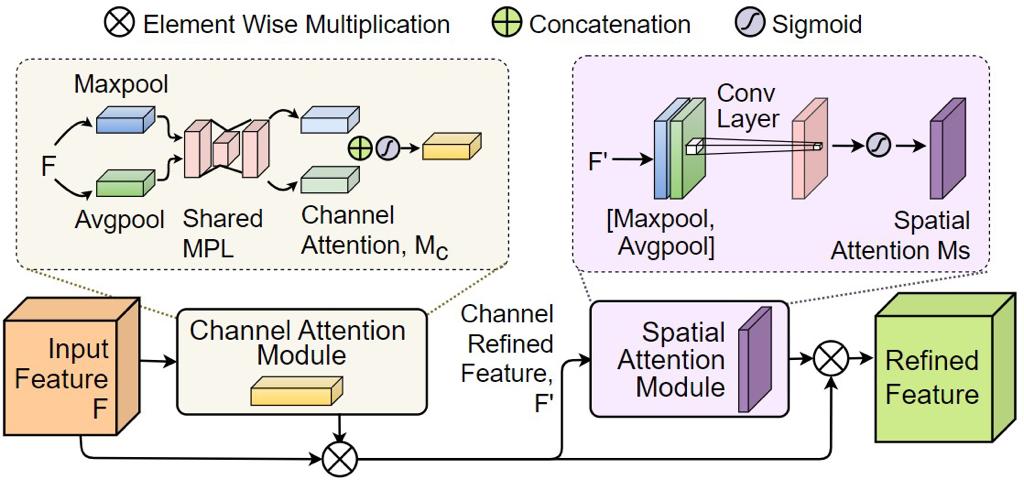

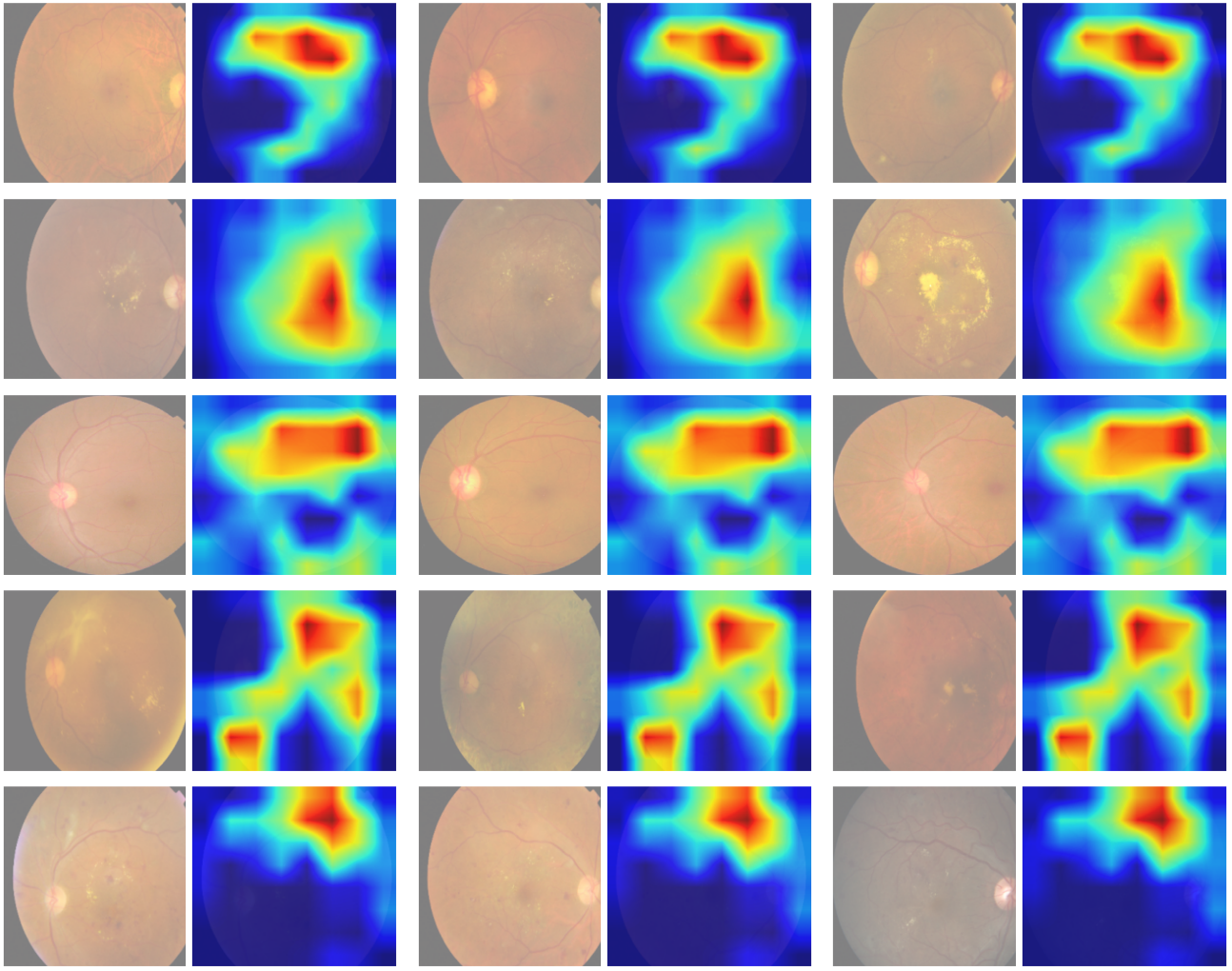
No objective provided.
No findings listed yet.
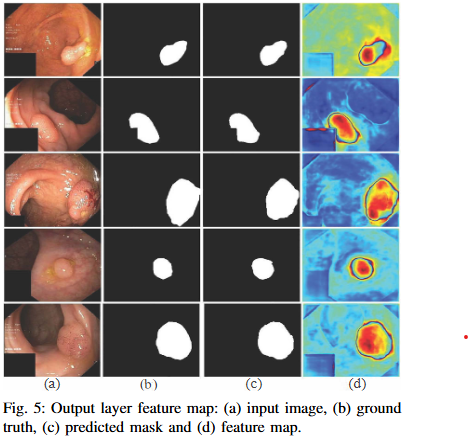
No ongoing projects in this area.

Algorithms and systems for visual understanding and perception.
Computer vision research at the lab explores the development of algorithms and systems capable of perceiving and understanding visual data in real-world environments. Topics include object detection, scene understanding, tracking, and visual reasoning. By integrating attention mechanisms, transformers, and graph neural networks, this work advances autonomous perception systems across domains such as healthcare, robotics, and intelligent surveillance, pushing the boundaries of visual cognition and artificial intelligence.
No objective provided.
No findings listed yet.
No objective provided.
No findings listed yet.
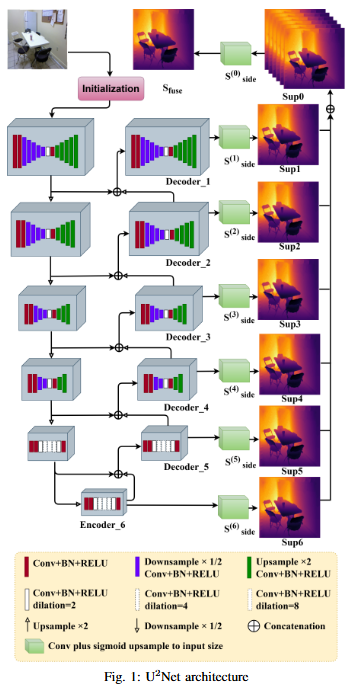

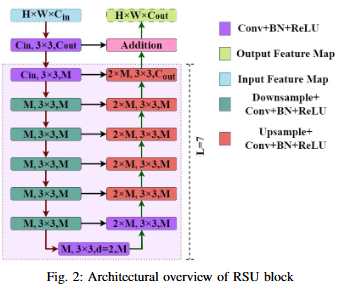
No objective provided.
No findings listed yet.
No ongoing projects in this area.

Earth observation and geospatial analysis from aerial and satellite imagery.
This research investigates the use of aerial and satellite imagery for earth observation and geospatial analysis. Deep neural networks are employed for tasks such as land cover classification, road and building extraction, and environmental monitoring. The goal is to develop accurate and scalable models capable of processing high-resolution satellite data, thereby supporting urban planning, disaster management, and sustainable resource monitoring with precision-driven remote sensing analytics.
No objective provided.
No findings listed yet.
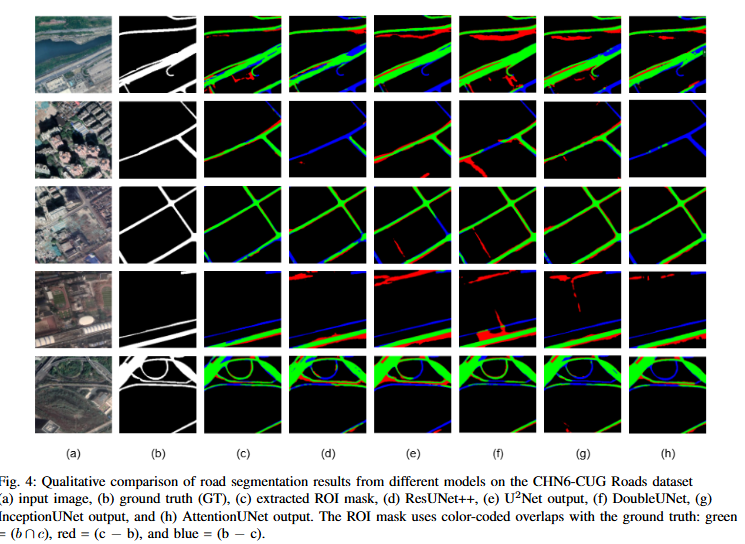
To develop SE-U2Net, a robust and efficient deep learning framework for road extraction from very high-resolution (VHR) satellite imagery by integrating the U²-Net architecture with Squeeze-and-Excitation (SE) modules, enabling selective channel refinement and multi-scale contextual feature learning without reliance on pre-trained backbones.
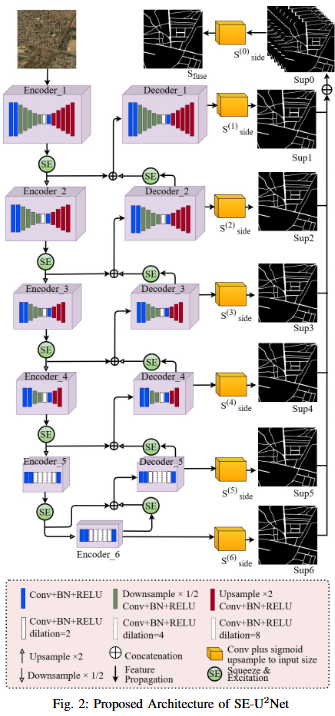

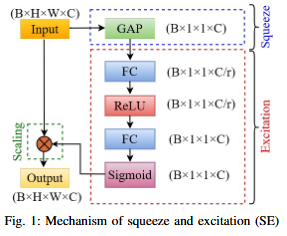
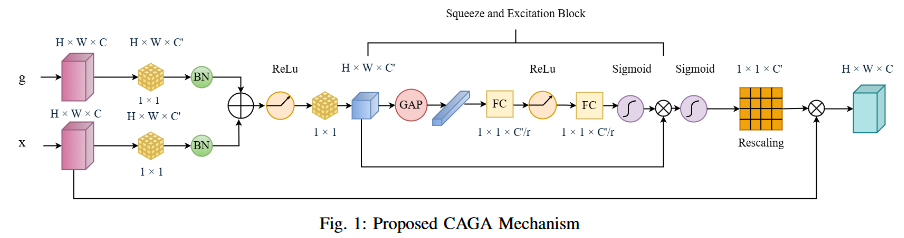
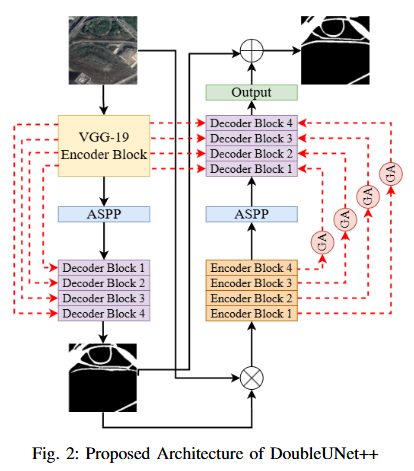
To develop DoubleUNet++, an enhanced road extraction model that improves the contextual understanding and spatial precision of remote sensing image segmentation by integrating a Channel-Aware Gated Attention (CAGA) mechanism and Squeeze-and-Excitation (SE) layers into the DoubleUNet architecture.

No ongoing projects in this area.

Data-driven modeling and analysis of biological systems.
The lab’s research in computational biology and bioinformatics applies machine learning and statistical modeling to the analysis of complex biological data. Efforts include protein structure prediction, gene expression analysis, and biological network modeling. Through the integration of omics data and imaging modalities, this area aims to uncover biological patterns and enhance understanding of disease mechanisms, ultimately contributing to precision medicine and drug discovery initiatives.
No objective provided.
No findings listed yet.
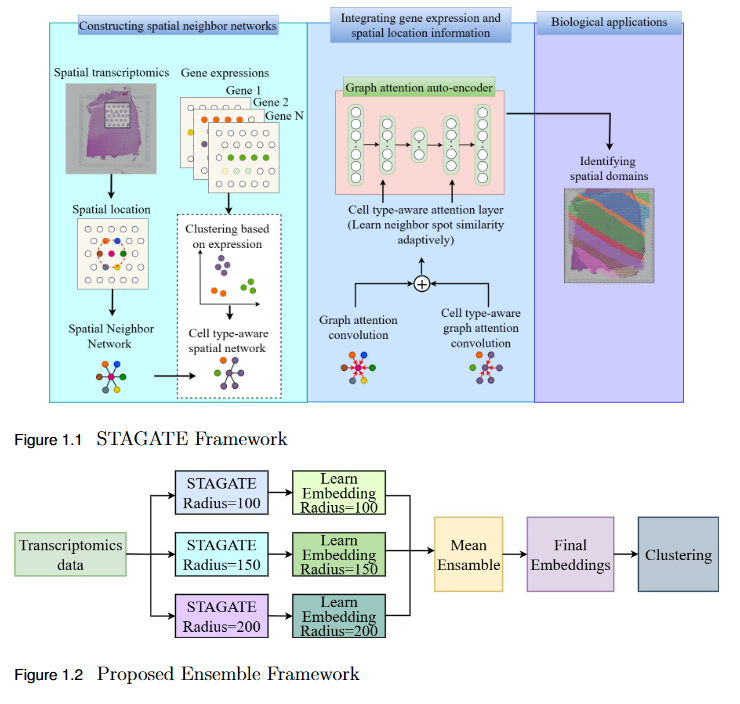
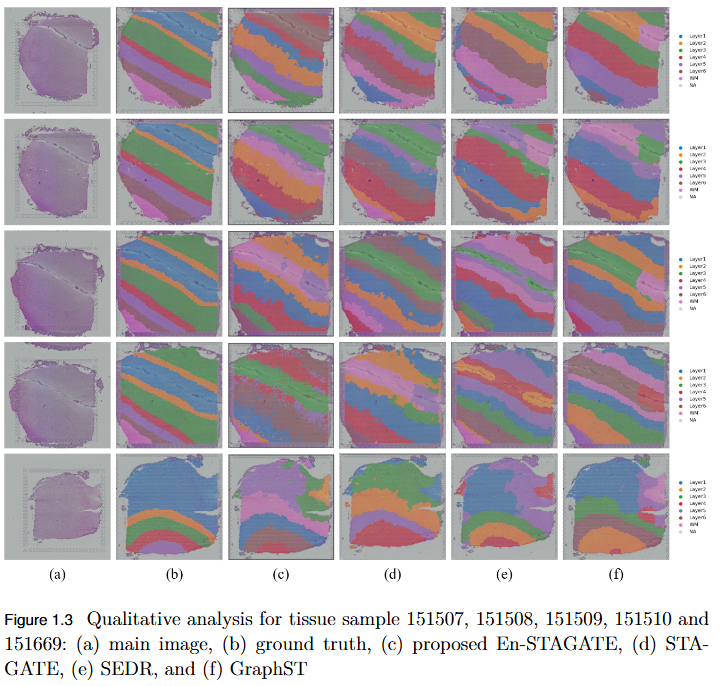
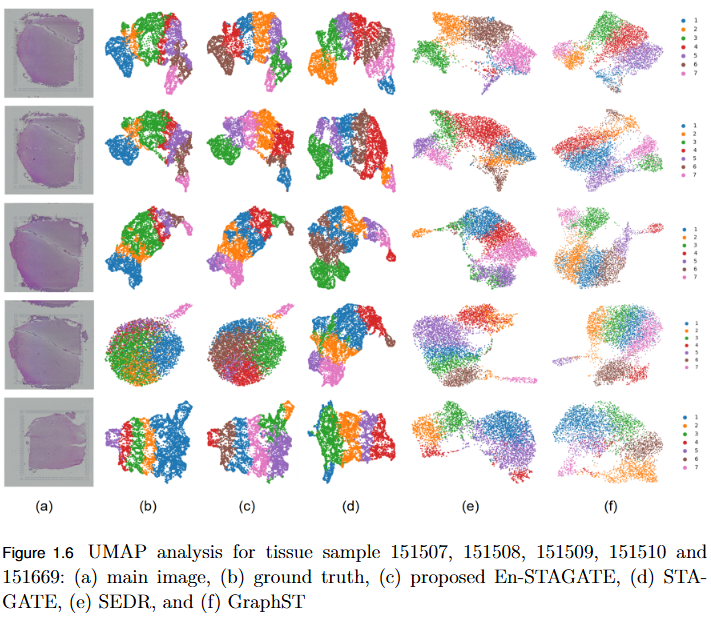
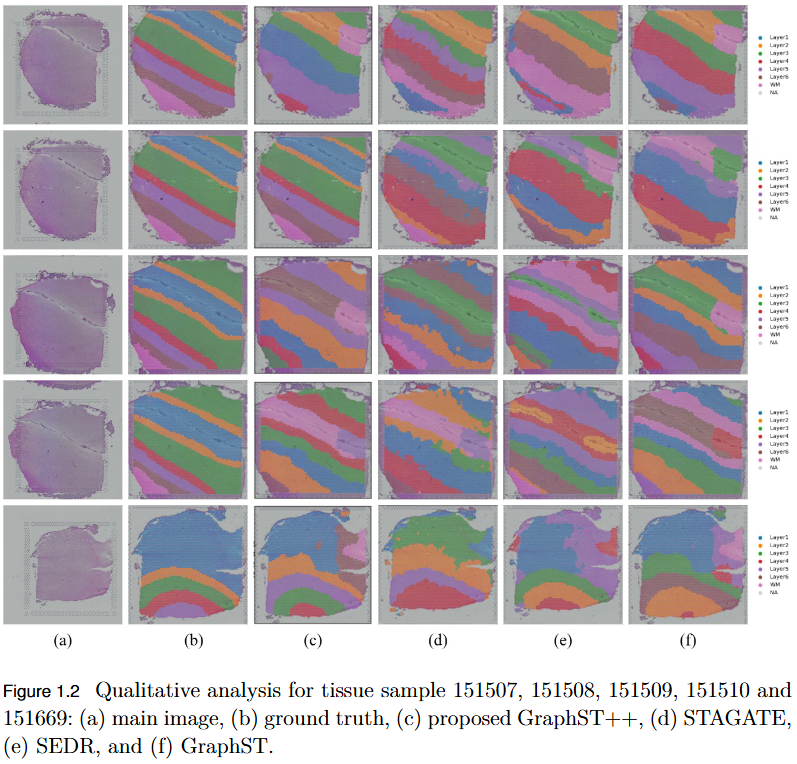
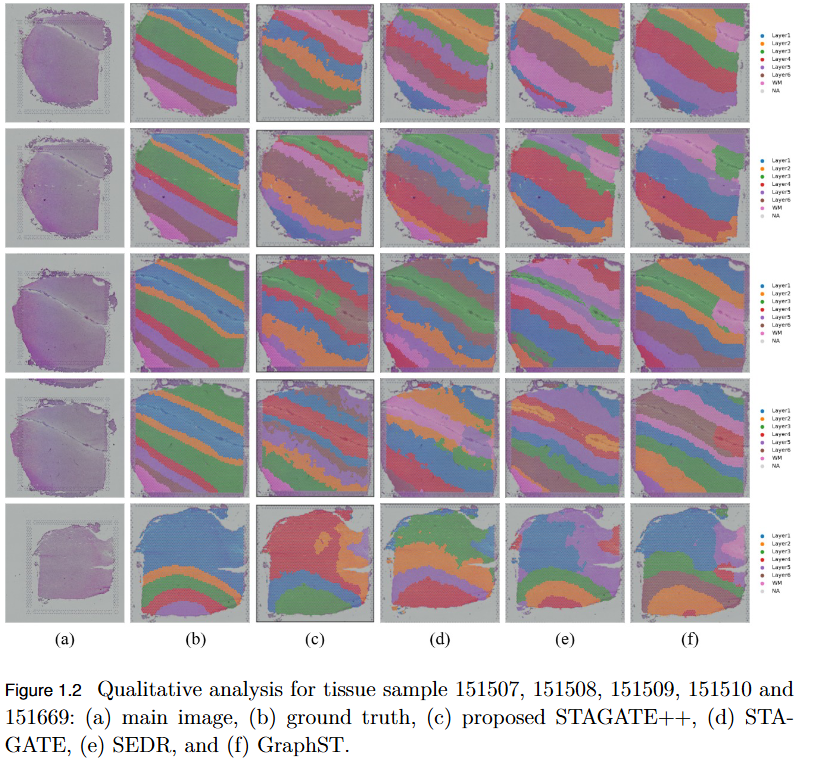
To systematically evaluate the performance and scalability of leading GNN-based spatial transcriptomics (ST) models—STAGATE, GraphST, and SEDR—on high-density next-generation datasets such as Stereo-seq and Slide-seq, and to identify their limitations in modeling complex spatial structures.
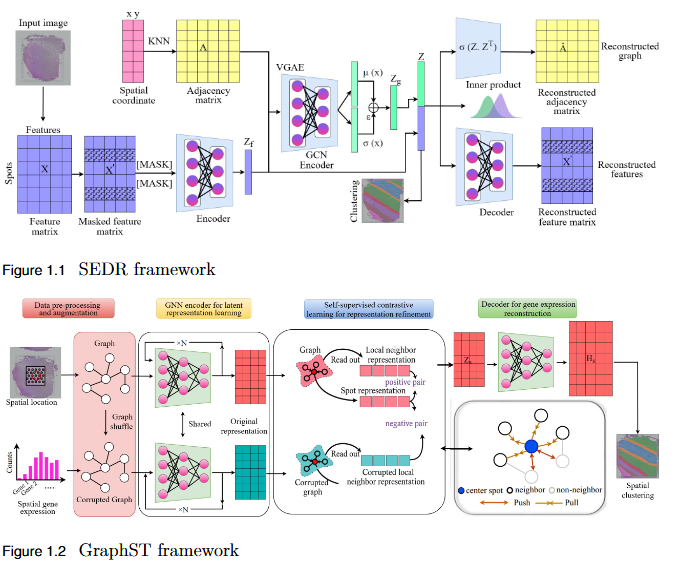
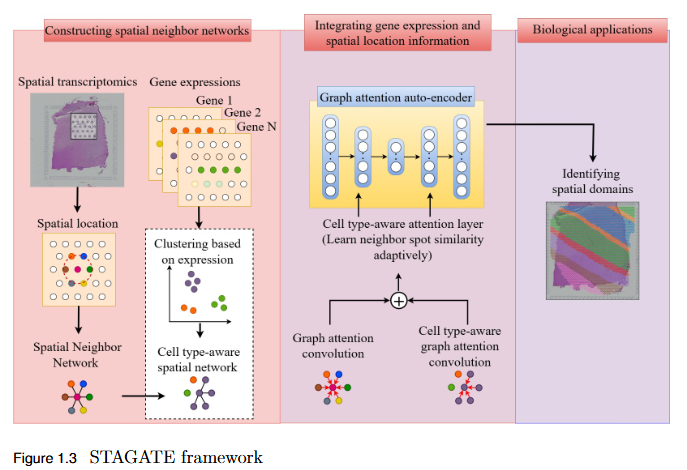
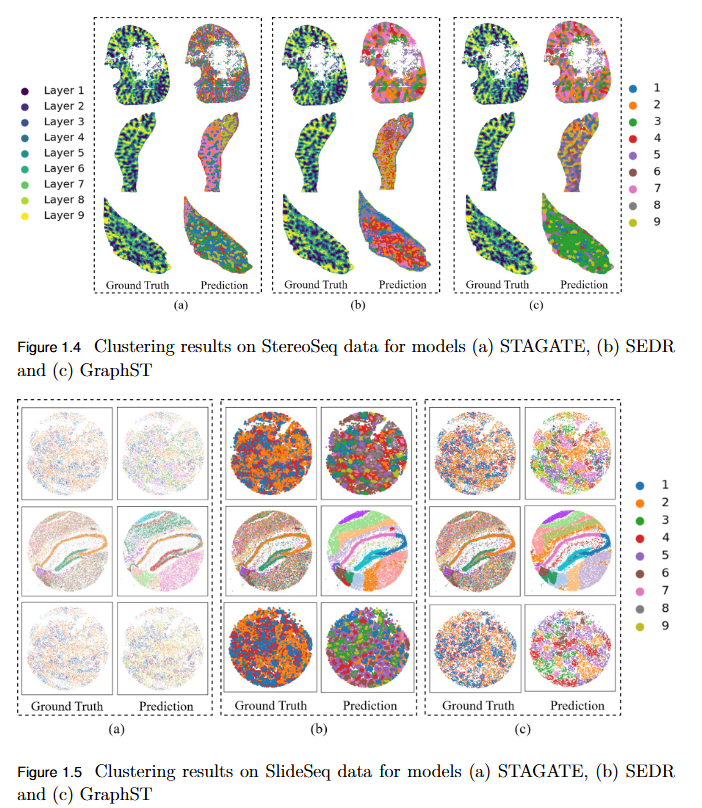
To overcome the limitation of fixed spatial neighborhood scales in existing spatial transcriptomics (ST) models by developing En-STAGATE, an ensemble framework that integrates multiple spatial graphs across varying neighborhood radii to capture both local and global tissue structures for improved domain identification.
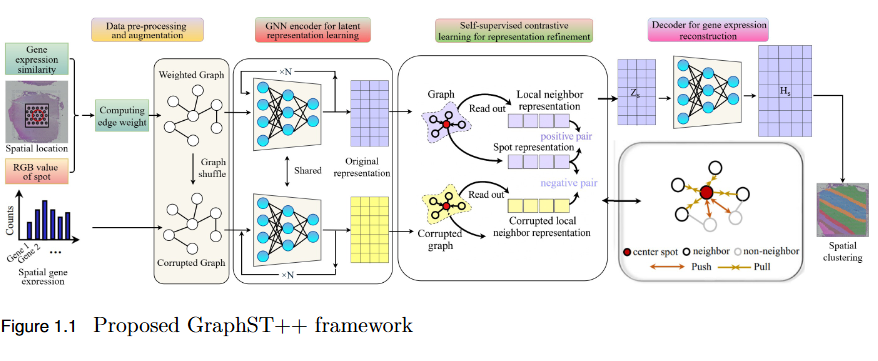
To address the over-smoothing and spatial bias in current spatial transcriptomics (ST) models by developing GraphST++, a multi-modal framework that integrates spatial, gene expression, and histological features for constructing biologically faithful tissue graphs.

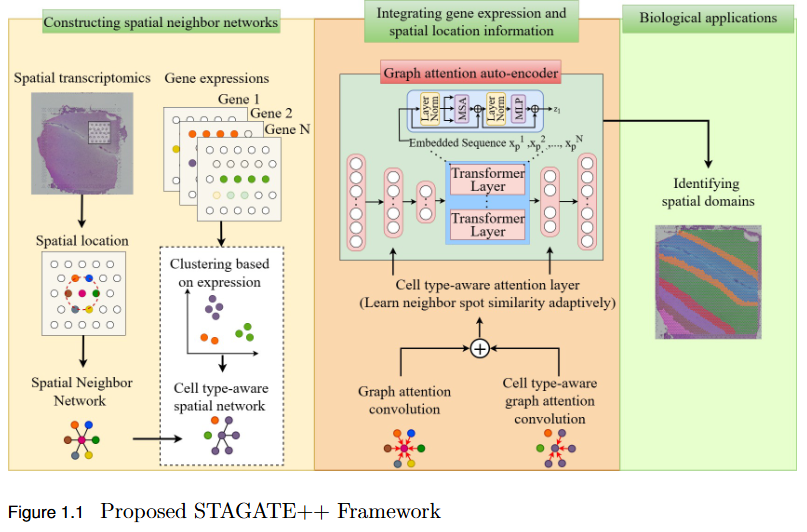
To overcome the limitation of existing graph-based spatial transcriptomics (ST) models in capturing long-range spatial dependencies by developing STAGATE++, a hybrid GAT–Transformer architecture that jointly learns local and global tissue representations.


Signal and image enhancement, restoration, and transformation techniques.
This foundational area focuses on the theoretical and practical aspects of image enhancement, restoration, compression, and transformation. Research includes spatial and frequency-domain techniques for noise reduction, contrast enhancement, and feature extraction. By combining classical methods with modern deep learning frameworks, the objective is to achieve efficient, high-quality image processing pipelines that serve as the backbone for advanced applications in computer vision, medical imaging, and multimedia analysis.
No objective provided.
No findings listed yet.
No objective provided.
No findings listed yet.
No ongoing projects in this area.